

Service discovery is how different services "learn" about each-other in order to connect.
A key problem in deployment is getting services to be able to find each-other. A database might be at 10.1.1.1:6543 while the webserver is at 10.1.1.2:8080. Things get more complicated as you add more copies of your webserver, or add entirely new services.
In the simplest case, you might be deploying something similar to the MERN (MongoDB, Express/React/Node.js) stack to launch a simple full-stack webapp. There are three services here:
- The database
- The backend (express/node.js)
- The frontend (often create-react-app as of 2021)

Here, there are three services that need to be discovered.
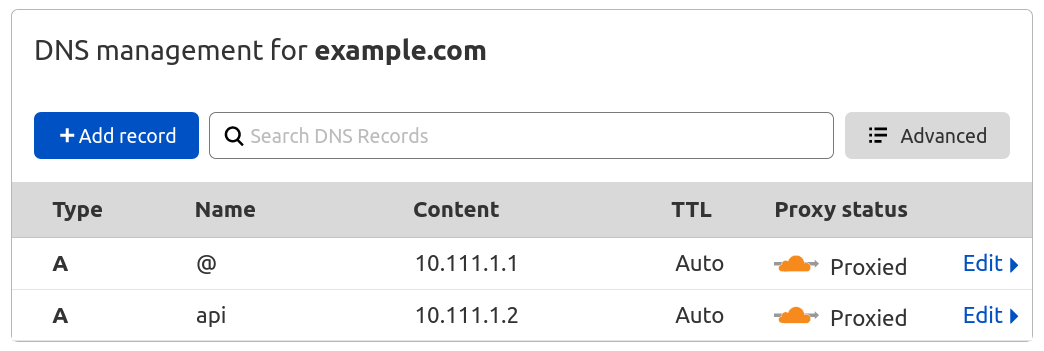
- The browser (end user) must learn that example.com is at some IP (10.111.1.1, for example)
- The browser (end user) must learn that api.example.com is at some IP (10.111.1.2, for example)
- The backend (node.js) must learn that the database is at some IP (10.111.1.3, for example)
Level one: No service discovery
In the very simplest configuration, everything is manually configured. The backend and frontend are at static IPs, and given hostnames within DNS, and the backend is configured to connect to MongoDB at a specific port:
//within the backend
mongoose.connect('mongodb://'+process.env["MONGODB_IP"]+':27017/myapp');#when starting the backend
MONGODB_IP=10.111.1.3 node backend.jsThis configuration is completely fine for simple products - it's difficult to mess up, is relatively secure, and doesn't overcomplicate things.
Level two: Service discovery via distributed hash table
You can go pretty far with this simple configuration. Most products could launch an MVP without service discovery.
You'll know you should care about service discovery when you start seeing one of the following:
- You want "zero downtime deployments" or to use other, more complex deployment strategies.
- You have more than a couple of microservices.
- You are deploying to several environments (e.g., dev/staging/ephemeral/production) and it's getting unwieldy
Let's focus on zero-downtime deployments because they are illustrative of the broader problem.
A little diversion: Reverse proxies and zero-downtime deployments
The idea for a zero-downtime deployment is simple:
- Start the a version of the backend and frontend.
- Wait until the new version is up, then divert the traffic to them.
- Shut off the old version of the backend and frontend.
However, it's difficult to update the IP addresses in our DNS provider for various reasons (DNS is can take days to update, so it's difficult to change things quickly)
The solution is to add a webserver that acts as the "gateway" to the frontend and backend. We'll be able to change where it points without causing any downtime or waiting. Webservers like these are called reverse proxies.



A straightforward approach: Store the service IPs in a hash table.
Implicitly in this process, we assumed that our reverse proxy would be able to know the IP of the new versions of our apps - this is the general problem of service discovery.
Instead of needing to manually tell our reverse proxy where the backend and frontend live, it would be convenient if we could automate everything. When the new versions come online, they could update the value for the key "backend" and "frontend" respectively with their own IPs, and then the reverse proxy could watch for changes to the table and use that for routing decisions.
For a more concrete example, assume you were using nginx as your reverse proxy, etcd as a key/value store, and confd to update the configuration:
server {
server_name example.com;
location / {
proxy_pass http://{{getv "/ips/frontend"}};
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
server {
server_name api.example.com;
location / {
proxy_pass http://{{getv "/ips/api"}};
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}All you'd have to do is update the code for your frontend to set /ips/frontend to be its IP, and make your backend do the same for /ips/backend.
That way when a new version would be started - the key in the table would be updated, and nginx which version of the frontend or backend it was "proxy passing" the requests to.
Problems with this approach
- It's complex: We've added three new dependencies that developers need to learn (nginx, etcd, and confd)
- It's error prone: It's easy to forget to update necessary keys, and it's complicated to update the keys if you are running multiple copies of each version of your services.
- It requires you to write custom configuration files: It's generally nicer to use the default configuration than it is to specify your own.
This leads us to the industry standard:
Level three: Service discovery via DNS
DNS-based service discovery is the industry standard: It's intuitive, doesn't require configuration files, and is often provided by your cloud provider or orchestrator.
Before we get into it, though, we need to talk about DNS a little bit.
Domain Name Service (DNS)
The idea for DNS is just to map hostnames to IPs.
When you visit webapp.io, for example, the global DNS system will first map the name webapp.io to the addresses (at the time of writing) 104.21.79.86 and 172.67.169.106:
colin:~$ dig webapp.io
; <<>> DiG 9.16.6-Ubuntu <<>> webapp.io
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27212
;; ANSWER SECTION:
webapp.io. 299 IN A 104.21.79.86
webapp.io. 299 IN A 172.67.169.106
Usually when people mention DNS, they mean the global service (i.e., visiting websites on the internet.) However - it's also possible to use DNS internally as well.
It'd be ideal if we could connect to "http://frontend" from our reverse proxy and have DNS respond with the IP for the correct version(s) of the frontend.
That's how DNS-based service discovery works. You configure your services to query a server you control for where things are:
//within backend, before DNS-based discovery:
mongoose.connect('mongodb://'+process.env["MONGODB_IP"]+':27017/myapp');
//now with DNS-based discovery:
mongoose.connect('mongodb://mongo:27017/myapp');Of course - it's not trivial to deploy your own DNS server in practice (though there are popular options like https://coredns.io/ )
In practice, you'd likely use AWS's solution if you were using AWS, or kubernetes' solution, for two popular examples.

Conclusion: Service discovery is tricky, but important.
If you configure service discovery in an appropriate manner for your deployment (e.g., dns-based for a kubernetes cluster), it makes it significantly easier for developers to have microservices talk to eachother.
Instead of a developer having to write "connect to MongoDB at 'mongodb://'+process.env["MONGODB_IP"]+':27017/myapp", they can simply say "Connect to MongoDB at 'mongodb://mongo:27017/myapp'"
By decoupling the application logic from the deployment logic, you'll help the developers on your team build better, bug free code.