

Making a filesystem seems daunting, but actually isn't that hard in 2022. In this article we'll talk about why we had to build our own filesystem, and chat about how you can build your own.
Docker builds are often slow
Dockerfiles come with several "foot guns" that can easily cripple build performance. The Dockerfile below, for example, will take many minutes to build after every single change:
FROM node:18
COPY . .
RUN npm install
CMD ["npm", "run", "start"]The reason is that Docker hashes each step. It figures out the inputs for every command, and makes a new hash for the layer based on the layer above.
How docker layer caching currently works
The hash function of the COPY command might look like this:
func Hash(h hash.Hash, sourceDir, destDir string) {
h.Write("COPY instruction to " + destDir)
filepath.WalkDir(sourceDir, func(path string, d fs.DirEntry, err error) error {
f, _ := os.Open(filepath.Join(sourceDir, path))
io.Copy(h, f)
f.Close()
})
}- Take the hash of the node:18 image,
- Add the fact that there's a COPY instruction to it,
- Add all of the files copied to it,
- Set the ID of the resulting build layer as that hash.
If you docker build again without changing the Dockerfile or any other files copied, you'll be able to skip the COPY instruction because the hash will match with the layer already built.
However, if you change any files read by the COPY instruction (e.g., any of them), Docker will have re-start from the COPY instruction and re-run the slow npm install command.
Ideally, the build would be able to figure out which files were read by which steps and only use those while calculating the hash.
A better way of skipping build steps?
Since npm install only reads a few files (like the node configuration file at package.json), it could be skipped as long as those particular files haven't changed.
The optimal caching strategy would be to hash files as they are read during the process of a step running, and then use those files to determine whether a snapshot could be loaded.

But how can you tell when files are read? Utilities like inotify have limits on how many files can be watched, and can miss reads made by other filesystems (such as overlayfs). You could maybe use eBPF or the audit subsystem, but these depend a lot on the kernel version for now.
FUSE passthrough monitoring FS
The easiest way to monitor which files are used at which build step is by making a new filesystem which just passes reads/writes to a parent filesystem and logs them.
Making filesystems was hard 10+ years ago, but is now significantly easier because of a kernel feature in many operating systems called FUSE (Filesystem In User SpacE). Fuse filesystems are just regular programs (usually written in C) that interact with the operating system to create new virtual filesystems at a directory.
There's already a reference implementation of "passthrough" in the official libfuse sources, so all we'd have to do is log when files are read:
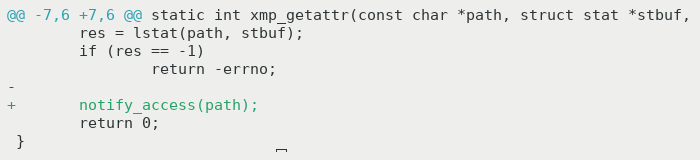
stat package.json, forward the request to another directory and log itIf we implemented builds this way, we could know with complete certainty which files were read by any process up to a given point.
How this system is better
Let's look at the Dockerfile above again:
FROM node:18
COPY . .
RUN npm install
CMD ["npm", "run", "start"]Now, when we build, COPY would not include any files in its hash, only the fact that a directory was copied.
On the subsequent line, npm install would read the file package.json from our FUSE filesystem, and we'd add the hash of package.json to a dictionary, and save it
If we edited some file somefile.js (or almost any other file) and built again, we'd be able to notice that the hash is the same, and the hashes of the read files is the same.

Is this approach implemented anywhere?
If you're hoping this lands in Docker any time soon, you might be disappointed. The modern container landscape is heavily based on 10 years of work with the original hash-only-based solution, and that structure has made it into the OCI specification which cloud providers use to allow you to run containers.
At webapp.io we've implemened this approach for our non-OCI-compliant "Dockerfiles that build VMs" language called Layerfiles, which we've been in the process of open sourcing.
How much difference does it make?
For toy examples like the one above with package.json, you can work around the issue if you know how the Docker caching model works by manually copying files or using .dockerignore. However, if you have a large monorepository with lots of things to build, it can be very difficult to micromanage which files are used by what.
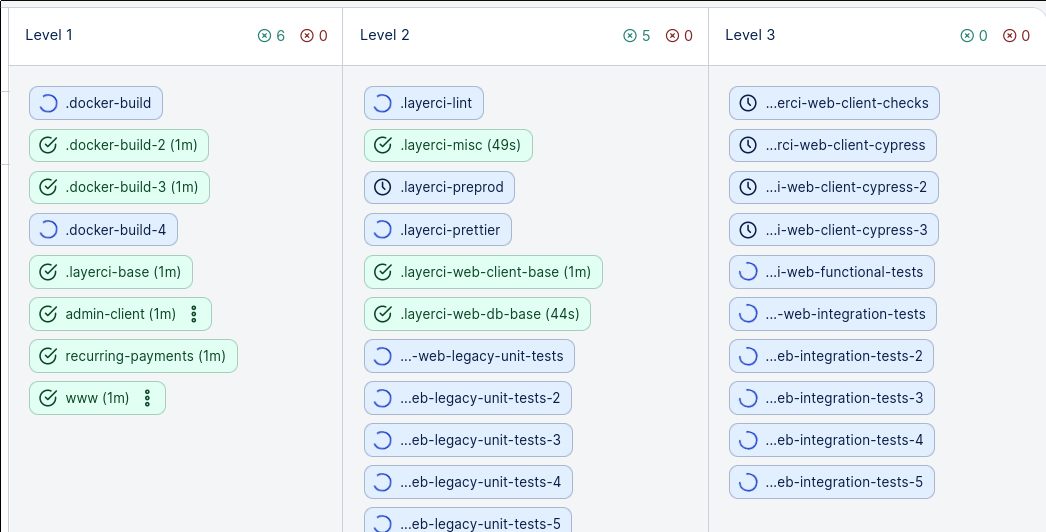
For our "Dockerfiles that build VMs" usecase, we've found that people add dozens of build steps in large repositories because they can assume that most of them will be skipped. This approach even acts as a replacement for "cache keys" of CI systems, if you build your resources on every commit like we do.
Conclusion
Docker build's cache is one of the most intuitive ways of speeding up builds, and one of the reasons Docker became popular in the first place.
That doesn't mean that there isn't room for improvement, and approaches like the one in this article will land in the coming years to make development even faster.